This week, we’re coming into the big turn in the class, from probability theory to sampling theory.
In the probability theory section of the course, we developed the theoreticallybest possible set of models. Namely, we said that if our goal is to produce a model that minimizes the Mean Squared Error that expectation and conditional expectation are as good as it gets. That is, if we only have the outcome series, \(Y\), we cannot possibly improve upon \(E[Y]\), the expectation of the random variable \(Y\). If we have additional data on hand, say \(X\) and \(Y\), then the best model of \(Y\) given \(X\) is the conditional expectation, \(E[Y|X]\).
We have also said that because this conditional expectation function might be complex, and hard to inform with data, that we might also be interested in a principled simplification of the conditional expectation function – the simplification that requires our model be a line.
With this simplification in mind, we derived the linear system that produces the minimum MSE: the ratio of covariance between variables to variance of the predictor:
\[
\beta_{BLP} = \frac{Cov[Y,X]}{V[X]}.
\]
We noted, quickly, that the simple case of only two variables – an outcome and a single predictor – generalizes nicely into the (potentially very) many dimensional case. If the many-dimensional \(BLP\) is denoted as \(g(\mathbf{X}) = b_{0} + b_{1}X_{1} + \dots + b_{k}X_{k}\), then we can arrive at the sloped between one particular predictor, \(X_{k}\), and the outcome, \(Y\), as:
You’re also done with your first test. Double Yay!
We’re going to have a second test in a few weeks. Then we’re done testing for the semester Yay?
5.1.2 Learning Objectives
At the end of this week, students will be able to
Understand what iid sampling is, and evaluate whether the assumption of iid sampling is sufficiently plausible to engage in frequentist modeling.
Appreciate that with iid sampling, summarizing functions of random variables are, themselves, random variables with probability distributions and values that they obtain.
Recall definition of an estimator, state and understand the desirable properties of estimators, and evaluate whether an estimator possesses those desirable properties.
Distinguish between the concepts of {expectation & sample mean}, {variance & unbiased sample variance estimator, sampling-based variance in the sample mean}.
5.1.3 Roadmap
5.1.3.1 Where We’re Going – Coming Attractions
We’re going to start bringing data into our work
First, we’re going to develop a testing framework that is built on sampling theory and reference distributions: these are the frequentist tests.
Second, we’re going to show that OLS regression is the sample estimator of the BLP. This means that OLS regression produces estimates of the BLP that have known convergence properties.
Third, we’re going combine the frequentist testing framework with OLS estimation to produce a full regression testing framework.
5.1.3.2 Where We’ve Been – Random Variables and Probability Theory
Statisticians create a model (also known as the population model) to represent the world. This model exists as joint probability densities that govern the probabilities that any series of events occurs at the same time. This joint probability of outcomes can be summarized and described with lower-dimensional summaries like the expectation, variance, covariance. While the expectation is a summary that contains information on about one marginal distribution (i.e. the outcome we are interested in) we can produce predictive models that update, or condition the expectation based on other random variables. This summary, the conditional expectation is the best possible (measured in terms of minimizing mean squared error) predictor of an outcome. We might simplify this conditional expectation predictor in many ways; the most common is to simplify to the point that the predictor is constrained to be a line or plane. This is known as the Best Linear Predictor.
5.1.3.3 Where we Are
We want to fit models – use data to set their parameter values.
A sample is a set of random variables
Sample statistics are functions of a sample, and they are random variables
Under iid and other assumptions, we get useful properties:
Statistics may be consistent estimators for population parameters
The distribution of sample statistics may be asymptotically normal
5.2 Key Terms and Assumptions
5.2.1 IID
We use an abbreviation for the sampling process that under girds our frequentist statistics. That abbreviation, IID, while short, contains two powerful requirements of our data sampling process.
IID sampling is:
Independent. The first I in the abbreviation, this independence requirement is similar to the independence concept that we’ve used in the probability theory section of the course. When samples are independent, the result of any one sample is not informative about the value of any of the other samples.
Identically Distributed. The ID in the abbreviation, this requirement means that all samples are drawn from the same distribution.
It might be tempting to imagine that IID samples are just “random samples”, but it is worth noting that IID sampling has the two specific requirements noted above, and that these requirements are more stringent than a “randomness” criteria.
When we are thinking about IID samples, and evaluating whether the sample do, in point of fact, meet both of the requirements, it is crucial to make an explicit statement about the reference population that is under consideration.
For example, suppose that you were interested in learning about life-satisfaction and your reference population are the peoples who live in the United States. Further, suppose that you decide to produce an estimate of this using a sample drawn from UC Berkeley undergraduate students during RRR week? There are several flaws in this design:
There is a key research design issue: a sample drawn from Berkeley undergraduates is going to be essentially uninformative of a US resident reference population!
There is a key statistical issue: the population of Berkeley undergraduates are not really an independent sample from the entire US resident reference population. Once you learn the age of someone from the Berkeley student population, you can make an conditional guess about the age of the next sample that will be closer than was possible before the first sample. The same goes for life-satisfaction: When you learn about the life-satisfaction from the first undergrad (who is miserable because they have their Stat 140 final coming up) while they are studying for their finals) you can make a conditionally better guess about the satisfaction of the next undergrad.
Notice that these violations of the IID requirements only arise because our reference population is the US resident population. If, instead, the reference population were “Berkeley undergrads” then the sampling process would satisfy the requirements of an IID process.
How, or why, can a change in the reference population make an identical sampling process move from one that we can consider IID to one that we cannot consider IID?
5.2.1.1 It this IID?
For each of the following scenarios, is the IID assumption plausible?
Call a random phone number. If someone answers, interview all persons in the household. Repeat until you have data on 100 people.
Call a random phone number, interview the person if they are over 30. Repeat until you have data on 100 people.
Record year-to-date price change for 20 largest car manufacturers.
Measure net exports per GDP for all 195 countries recognized by the UN.
5.3 Estimators
In our presentation of this week’s materials, we choose to switch the presentation of statistics and estimators, electing to discuss properties that we would like estimators to posses, before we actually introduce any specific estimators.
5.3.1 Three properties of estimators
What are the three desirable properties of estimators?
Is one these properties more important than another? If you had to force-rank these properties in terms of their importance, which is the most, and which the least important? Why?
5.4 Estimator Property: Biased or Unbiased?
First, for a general case: Suppose that you have chosen some particular estimator, \(\hat{\theta}\) to estimate some characteristic, \(\theta\) of a random variable. How do you know if this estimator is unbiased?
Second, for a specific case: Define the “sample average” to be the following: \(\frac{1}{n}\sum_{i=1}^{N} x_{i}\). Prove that this sample average estimator is an unbiased estimator of \(E[X]\).
Third (easier), for a different specific case: Define the “smample smaverage” to be the following \(\frac{1}{n^2}\sum_{i=1}^{N} x_{i}\). Prove that the smample smaverage is a biased estimator of \(E[X]\).
Fourth (harder): Define the geometric mean to be \[\left(\prod_{i=1}^{N}x_{i}\right)^{\frac{1}{N}}\]. Prove that the geometric mean is a biased estimator of \(E[X]\).
5.4.1 Is it unbiased, with data?
Suppose that you’re getting data from the following process:
Notice that, there are two forms of inherent uncertainty in this function:
There is uncertainty about the distribution that we are getting draws from; and,
Within a distribution, we’re getting draws at random from a population distribution.
This class of function, the r* functions, are the implementation of random generative processes within the R language. Look into ?distributions as a class to see more about this process.
Suppose that you chose to use the same sample average estimator as a means of producing an estimate of the population expected value, \(E[X]\). Suppose that you get the following draws:
draws <-random_distribution(number_samples=10)draws
Is this sample average an unbiased estimator for the population expected value? How do you know?
5.5 Estimator Property: Consistency
Foundations makes another of their jokes when they write, on page 105,
“Consistency is a simple notion: if we had enough data, the probability that our estimate \(\hat{\theta}\) would be far from the truth, \(\theta\), would be small.”
How do we determine if a particular estimator,\(\hat{\theta}\) is a consistent estimator for our parameter of interest?
There are at least two ways:
The estimator is unbiased, and has a sampling variance that decreases as we add data; or,
We can use Chebyshev’s to place a bound on the estimator, showing that as we add data, the estimator converges in probability to \(\theta\).
The first notion of convergence requires an understanding of sampling variance:
The sampling variance of an estimator is a statement about how much dispersion due to random sampling, is present in the estimator. We defined the variance of a random variable to be \(E\left[(X - E[X])^{2}\right]\), The sampling variance uses this same definition, but we work with it slightly differently when we are considering sampling variance.
In particular, when we are considering sampling variance, we do not typically got as far as actually computing the variance of the underlying random variable? Why? Because, if we’re working in a sampling scenario, it is unlikely that we have access to the underlying function that governs the PDF of the random variable.
Instead, we typically start from a statement of the estimator that is under consideration, and apply the variance operator against that estimator. Consider, for example, forming a statement about the sampling variance of the sample average.
Let \(\overline{X} \equiv\) “sample average” \(\equiv \frac{1}{n}\sum_{i=1}^{n}X_{i}\) be the normal form of the sample average.
Earlier, we proved that \(\overline{X}\) is an unbiased estimator of \(E[X]\).
What is the sampling variance of the sample average?
Using the statement that you have just produced, would you say that the sample average is a consistent estimator for the population expectation of a random variable?
5.6 Understanding Sampling Distributions
How do sampling distributions change as we add data to them? This is going to both motivate convergence, and also play forward into the Central Limit Theorem. Let’s work through an example that begins with a case that we can think through and draw ourselves. Once we feel pretty good about the very small sample, then we will rely on R to do the work when we expand the example beyond what we can draw ourselves.
Suppose that \(X\) is a Bernoulli random variable representing an unfair coin. Suppose that the coin has a 70% chance of coming up heads: \(P(X=1) = 0.7\).
To begin, suppose that you take that coin, and you toss it two times: you have an iid sample of size 2, \((X_1,X_2)\).
What is the sampling distribution of the sample average, of this sample of size two?
On the axes below, draw the probability distribution of \(\overline X = \frac{X_1+X_2}{2}\).
What if you took four samples? What would the sampling distribution of \(\overline{X}\) look like? Draw this onto the axis above.
Explain the difference between a population distribution and the sampling distribution of a statistic.
Why do we want to know things about the sampling distribution of a statistic?
We are going to write a function that, essentially, just wraps a built-in function with a new name and new function arguments. This is, generally, bad coding practice – because it is changing the default lexicon than a collaborator needs to be aware of – but it is useful for teaching purposes here.
The number_of_simulations argument to the toss_coin function basically just adjusts the precision of our simulation study.
Let’s set, and keep this at \(1000\) simulations. But, if you’re curious, you could set this to be \(5\), or \(10\) and evaluate what happens.
toss_coin <-function(number_of_simulations=1000, number_of_tosses=2, prob_heads=0.7) { ## number of simulations is just how many times we want to re-run the experiment## number of tosses is the number of coins we're going to toss. number_of_heads <-rbinom(n=number_of_simulations, size=number_of_tosses, prob=prob_heads) sample_average <- number_of_heads / number_of_tossesreturn(sample_average)}toss_coin(number_of_simulations=10, number_of_tosses=2, prob_heads=0.7)
In the plot that you have drawn above, pick some value, \(\epsilon\) that is the distance away from the true expected value of this distribution.
What proportion of the sampling distribution is further away than \(E[X] \pm \epsilon\)?
When we toss the coin only two times, we can quickly draw out the distribution of \(\overline{X}\), and can form a statement about the \(P(E[X] - \epsilon \leq \overline{X} \leq E[X] + \epsilon)\).
What if we toss the coin ten times? We can still use the IID nature of the coin to figure out the true\(P(\overline{X} = 0), P(\overline{X} = 1), \dots, P(\overline{X} = 10)\), but it is going to start to take some time. This is where we rely on the simulation to start speeding up our learning.
As we toss more and more coins, \(\overline X_{(100)} \rightarrow \overline X_{(10000)}\) what will the value of \(\overline X\) get closer to? What law generates this, and why does this law generate this result?
5.7 Write Code to Demo the Central Limit Theorem (CLT)
When you were reading for this week, did you sense the palpable joy of the authors when they were writing about the central limit theorem?
We now preset what is often considered the most profound and important theorem in statistics.
Wow. What excitement.
On its own, the result that across a broad range of generative functions the distribution of sample averages converges in distribution to follow a normal distribution would be a statistical curiosity. Along the lines of “did you know that dinosaurs might have had feathers,” or, “avocado trees reproduce using ’protogynous dichogamy”. While these factoids might be useful on your quiz-bowl team, they don’t get us very far down the line as practicing data scientists.
However, there is a very useful consequence of this convergence in distribution that we will explore in detail over the coming two weeks: because so many distributions produce sample averages that converge in distribution to a normal distribution, we can put together a testing framework for sample averages that works for an agnostic set of random variables. Wait for that next week, but know that there’s a reason that we’re as excited about this statement as we are.
5.7.1 Part 1
To begin with, we will use fair coins that have an equal probability landing heads and tails.
Modify the function argument below so that it conduct one simulations, and in each simulation tosses ten coins, each with an equal probability of landing heads and tails. Look into the toss_coin function: is there a point that this function is producing a sample average? If so, where?
Save values from the toss_coin function into an object, called sample_mean.
# toss_coin()
The sample mean is a random variable – it is a function that maps from a random generative process’ sample space (the number of heads shown on dice) to the real numbers. To try to make this clear, visualize a larger number of simulations on the toss_coin function. That is, increase the number_of_simulations to be 10, or 100. and plot a histogram of the results. This is quite similar to what we have done earlier.
# toss_coin()
If you replicate the simulation with ten coins enough times, will the distribution ever look normal? Why or why not?
5.7.2 Part 2
For this part, we’ll continue to study a fair coin.
What happens if you change the number of coins that you’re tossing? Here, set number_of_simulations=1000, and examine what happens if you alter the number of coins that you’re tossing? Is there a point where this distribution starts to “look normal” to you? (Later in the semester, we’ll formalize a test for this “looks normal” concept).
5.7.3 Part 3
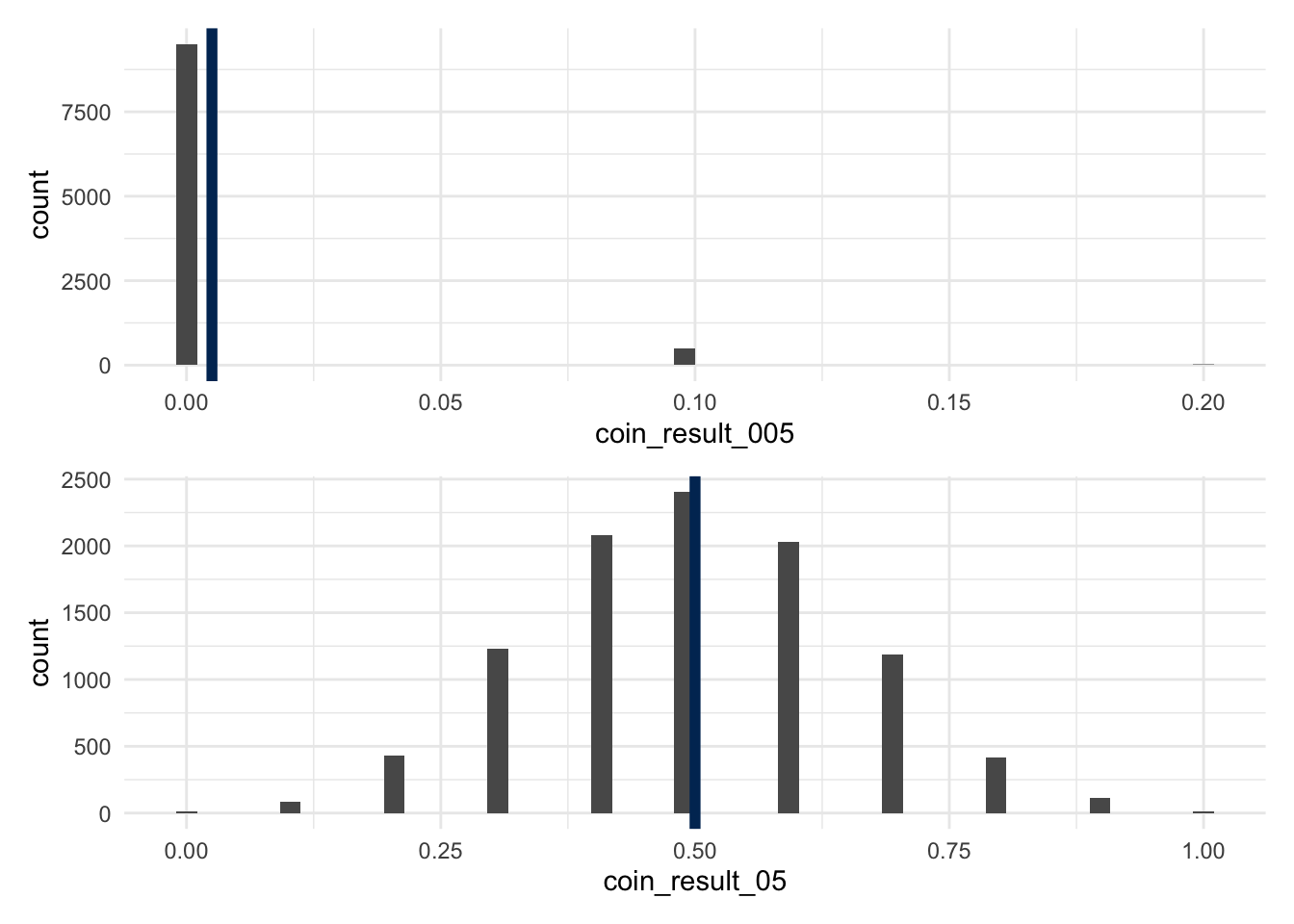
What would happen if the coin was very, very unfair? For this part, study a coin that has a prob_heads=0.01. This is an example of a highly skewed random variable.
Start your study here tossing three coins, number_of_coins=3. What does this distribution look like?
What happens as you increase the number of coins that you’re tossing? Is there a point that the distribution starts to look normal?
5.7.4 Discussion Questions About the CLT
How does the skewness of the population distribution affect the applicability of the Central Limit Theorem? What lesson can you take for your practice of statistics?
Name a variable you would be interested in measuring that has a substantially skewed distribution.
One definition of a heavy tailed distribution is one with infinite variance. For example, you can use the rcauchy command in R to take draws from a Cauchy distribution, which has heavy tails. Do you think a “heavy tails” distribution will follow the CLT? What leads you to this intuition?
5.8 Errors with Standard Errors
Talking about variance and sampling variance is hard, because the terms sound very similar, but have important distinctions in what they mean. For example, the “variance” is not the same as the “unbiased sample variance” which is also not the same as the “sampling variance of the sample average”. :sob:
Standard errors are a statement about the sampling variance of the sample average. But, related to this concept are the ideas of the Population Variance, the Plug-In Estimator for the Sample Variance, the Unbiased Sample Variance, and, finally, the Sampling Variance of the Sample Average (i.e the Standard Error).
How are each of these concepts related to one another, and how can we keep them all straight? As a group, fill out the following columns?
For the Estimator Properties column, here we’re considering, principally biased/unbiased and consistent/inconsistent.