library(tidyverse)
library(wooldridge)
library(car)
library(lmtest)
library(sandwich)
library(stargazer)12 The Classical Linear Model
12.1 Learning Objectives
At the end of this week’s learning students will be able to
- Describe the assumptions of the classical linear model (sometimes referred to as the Gauss-Markov Assumptions) and what each assumption contributes to the estimator.
- Evaluate using empirical methods, whether each of the assumptions are likely to be true of the population data generating function.
- Assess whether the guarantees that are provided by the classical linear model’s requirements are likely to ever be true, including within data the student is likely to encounter.
12.2 Class Announcements
- Lab 2 Deliverable and Dates
- Research Proposal (Today)
- Within-Team Review (Week 14)
- Final Report (Week 14)
- Final Presentation (Week 14)
12.3 Roadmap
Rearview Mirror
- Statisticians create a population model to represent the world.
- The BLP is a useful summary for a relationship among random variables.
- OLS regression is an estimator for the Best Linear Predictor (BLP).
- For a large sample, we only need two mild assumptions to work with OLS
- To know coefficients are consistent
- To have valid standard errors, hypothesis tests
Today
- The Classical Linear Model (CLM) allows us to apply regression to smaller samples.
- The CLM requires more to be true of the data generating process, to make coefficients, standard errors, and tests meaningful in small samples.
- Understanding if the data meets these requirements (often called assumptions) requires considerable care.
Looking Ahead
- The CLM – and the methods that we use to evaluate the CLM – are the basis of advanced models (inter alia time-series)
- (Week 13) In a regression studies (and other studies), false discovery is a widespread problem. Understanding its causes can make you a better member of the scientific community.
12.4 The Classical Linear Model
Comparing the Large Sample Model and the CLM
12.4.1 Part 1
- We say that in small samples, more needs be true of our data for OLS regression to “work.”
- What do we mean when we say “work”?
- If our goals are descriptive, how is a “working” estimator useful?
- If our goals are explanatory, how is a “working” estimator useful?
- If our goals are predictive, are the requirements the same?
- What do we mean when we say “work”?
12.4.2 Part 2
- Suppose that you’re interested in understanding how subsidized school meals benefit under-resourced students in San Francisco East Bay region.
- Using the tools from DATASCI 201, refine this question to a data science question.
- Suppose that there exists two possible data sources to answer the question you have formed:
- A large amount (e.g. 10,000 data points) of individual-level data about income, nutrition and test scores, self-reported by individual families who have opted in to the study.
- A relatively smaller amount (e.g. 500 data points) of Government data about school district characteristics, including district-level college achievement; county-level home prices, and state-level tax receipts.
- A large amount (e.g. 10,000 data points) of individual-level data about income, nutrition and test scores, self-reported by individual families who have opted in to the study.
- What are the tradeoffs to using one or the other data source?
12.4.3 Part 3
- Suppose you elect to use the relatively larger sample of individual-level data.
- Which of the large-sample assumptions do you expect are valid, and which are problematic?
- Or, suppose that you elect to use the relatively smaller sample of school-district-level data.
- Which of the CLM assumptions do you expect are valid, and which do you expect are most problematic?
- What was the research question that you identified?
- What would a successful answer accomplish?
12.4.4 Part 4
- Which data source, the individual or the district-level, do you think is more likely to produce a successful answer?
12.4.5 Part 5
Problems with the CLM Requirements
There are five requirements for the CLM
- IID Sampling
- Linear Conditional Expectation
- No Perfect Collinearity
- Homoskedastic Errors
- Normally Distributed Errors
For each of these requirements:
- Identify one concrete way that the data might not satisfy the requirement.
- Identify what the consequence of failing to satisfy the requirement would be.
- Identify a path forward to satisfy the requirement.
12.5 R Exercise
If you haven’t used the mtcars dataset, you haven’t been through an intro applied stats class!
In this analysis, we will use the mtcars dataset which is a dataset that was extracted from the 1974 Motor Trend US magazine, and comprises fuel consumption and 10 aspects of automobile design and performance for 32 automobiles (1973-74 models). The dataset is automatically available when you start R.
For more information about the dataset, use the R command: help(mtcars)
data(mtcars)
glimpse(mtcars)Rows: 32
Columns: 11
$ mpg <dbl> 21.0, 21.0, 22.8, 21.4, 18.7, 18.1, 14.3, 24.4, 22.8, 19.2, 17.8,…
$ cyl <dbl> 6, 6, 4, 6, 8, 6, 8, 4, 4, 6, 6, 8, 8, 8, 8, 8, 8, 4, 4, 4, 4, 8,…
$ disp <dbl> 160.0, 160.0, 108.0, 258.0, 360.0, 225.0, 360.0, 146.7, 140.8, 16…
$ hp <dbl> 110, 110, 93, 110, 175, 105, 245, 62, 95, 123, 123, 180, 180, 180…
$ drat <dbl> 3.90, 3.90, 3.85, 3.08, 3.15, 2.76, 3.21, 3.69, 3.92, 3.92, 3.92,…
$ wt <dbl> 2.620, 2.875, 2.320, 3.215, 3.440, 3.460, 3.570, 3.190, 3.150, 3.…
$ qsec <dbl> 16.46, 17.02, 18.61, 19.44, 17.02, 20.22, 15.84, 20.00, 22.90, 18…
$ vs <dbl> 0, 0, 1, 1, 0, 1, 0, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 0,…
$ am <dbl> 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 0, 0,…
$ gear <dbl> 4, 4, 4, 3, 3, 3, 3, 4, 4, 4, 4, 3, 3, 3, 3, 3, 3, 4, 4, 4, 3, 3,…
$ carb <dbl> 4, 4, 1, 1, 2, 1, 4, 2, 2, 4, 4, 3, 3, 3, 4, 4, 4, 1, 2, 1, 1, 2,…mtcars mpg cyl disp hp drat wt qsec vs am gear carb
Mazda RX4 21.0 6 160.0 110 3.90 2.620 16.46 0 1 4 4
Mazda RX4 Wag 21.0 6 160.0 110 3.90 2.875 17.02 0 1 4 4
Datsun 710 22.8 4 108.0 93 3.85 2.320 18.61 1 1 4 1
Hornet 4 Drive 21.4 6 258.0 110 3.08 3.215 19.44 1 0 3 1
Hornet Sportabout 18.7 8 360.0 175 3.15 3.440 17.02 0 0 3 2
Valiant 18.1 6 225.0 105 2.76 3.460 20.22 1 0 3 1
Duster 360 14.3 8 360.0 245 3.21 3.570 15.84 0 0 3 4
Merc 240D 24.4 4 146.7 62 3.69 3.190 20.00 1 0 4 2
Merc 230 22.8 4 140.8 95 3.92 3.150 22.90 1 0 4 2
Merc 280 19.2 6 167.6 123 3.92 3.440 18.30 1 0 4 4
Merc 280C 17.8 6 167.6 123 3.92 3.440 18.90 1 0 4 4
Merc 450SE 16.4 8 275.8 180 3.07 4.070 17.40 0 0 3 3
Merc 450SL 17.3 8 275.8 180 3.07 3.730 17.60 0 0 3 3
Merc 450SLC 15.2 8 275.8 180 3.07 3.780 18.00 0 0 3 3
Cadillac Fleetwood 10.4 8 472.0 205 2.93 5.250 17.98 0 0 3 4
Lincoln Continental 10.4 8 460.0 215 3.00 5.424 17.82 0 0 3 4
Chrysler Imperial 14.7 8 440.0 230 3.23 5.345 17.42 0 0 3 4
Fiat 128 32.4 4 78.7 66 4.08 2.200 19.47 1 1 4 1
Honda Civic 30.4 4 75.7 52 4.93 1.615 18.52 1 1 4 2
Toyota Corolla 33.9 4 71.1 65 4.22 1.835 19.90 1 1 4 1
Toyota Corona 21.5 4 120.1 97 3.70 2.465 20.01 1 0 3 1
Dodge Challenger 15.5 8 318.0 150 2.76 3.520 16.87 0 0 3 2
AMC Javelin 15.2 8 304.0 150 3.15 3.435 17.30 0 0 3 2
Camaro Z28 13.3 8 350.0 245 3.73 3.840 15.41 0 0 3 4
Pontiac Firebird 19.2 8 400.0 175 3.08 3.845 17.05 0 0 3 2
Fiat X1-9 27.3 4 79.0 66 4.08 1.935 18.90 1 1 4 1
Porsche 914-2 26.0 4 120.3 91 4.43 2.140 16.70 0 1 5 2
Lotus Europa 30.4 4 95.1 113 3.77 1.513 16.90 1 1 5 2
Ford Pantera L 15.8 8 351.0 264 4.22 3.170 14.50 0 1 5 4
Ferrari Dino 19.7 6 145.0 175 3.62 2.770 15.50 0 1 5 6
Maserati Bora 15.0 8 301.0 335 3.54 3.570 14.60 0 1 5 8
Volvo 142E 21.4 4 121.0 109 4.11 2.780 18.60 1 1 4 212.5.1 Questions:
- Using the
mtcarsdata, quickly reason about the variables that we’re interested in studying:
mtcars %>%
ggplot() +
aes(x=mpg) +
geom_histogram(bins=10)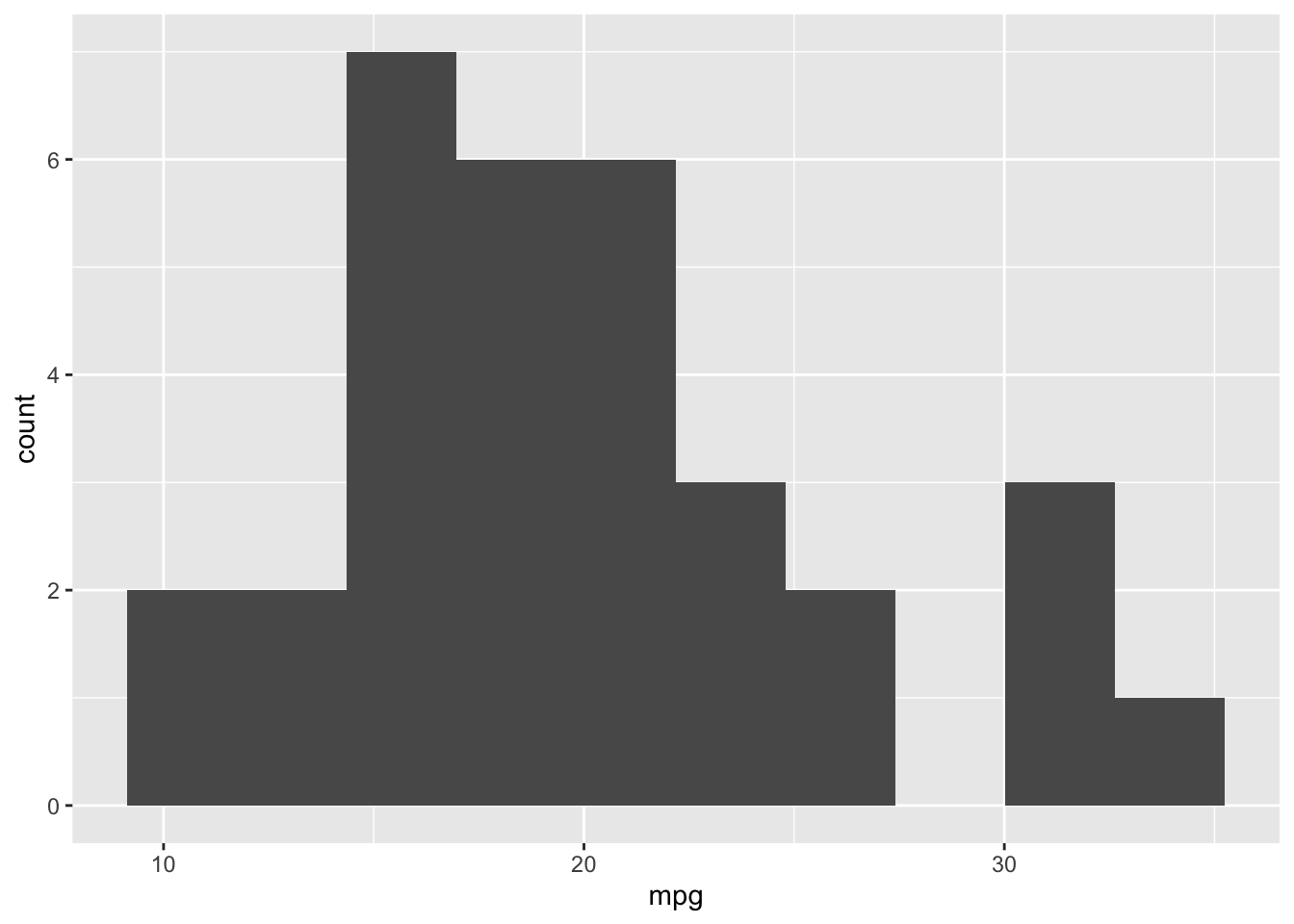
mtcars |> pairs()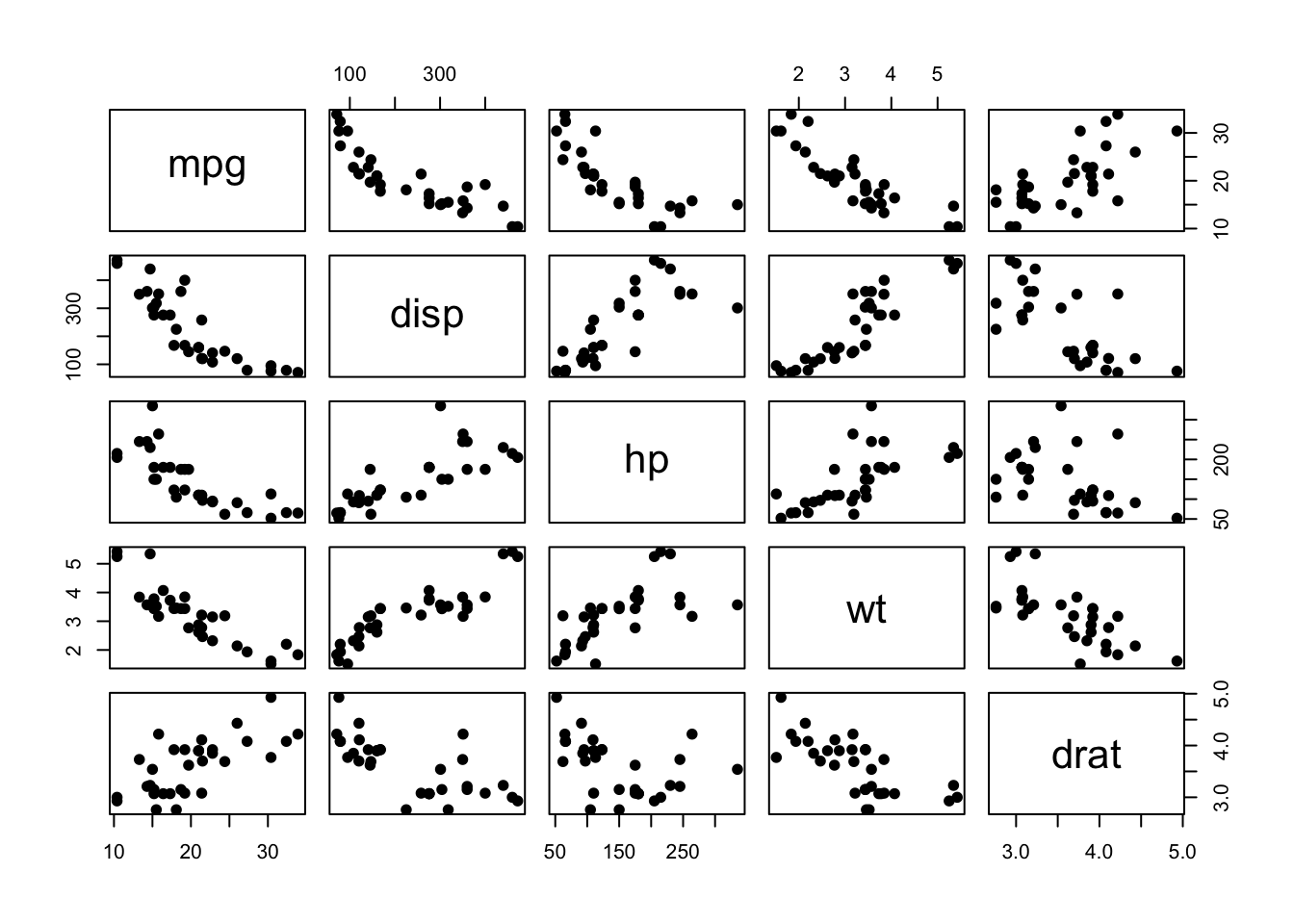
mtcars %>%
select(mpg, disp, hp, wt, drat) %>%
pairs(pch=19)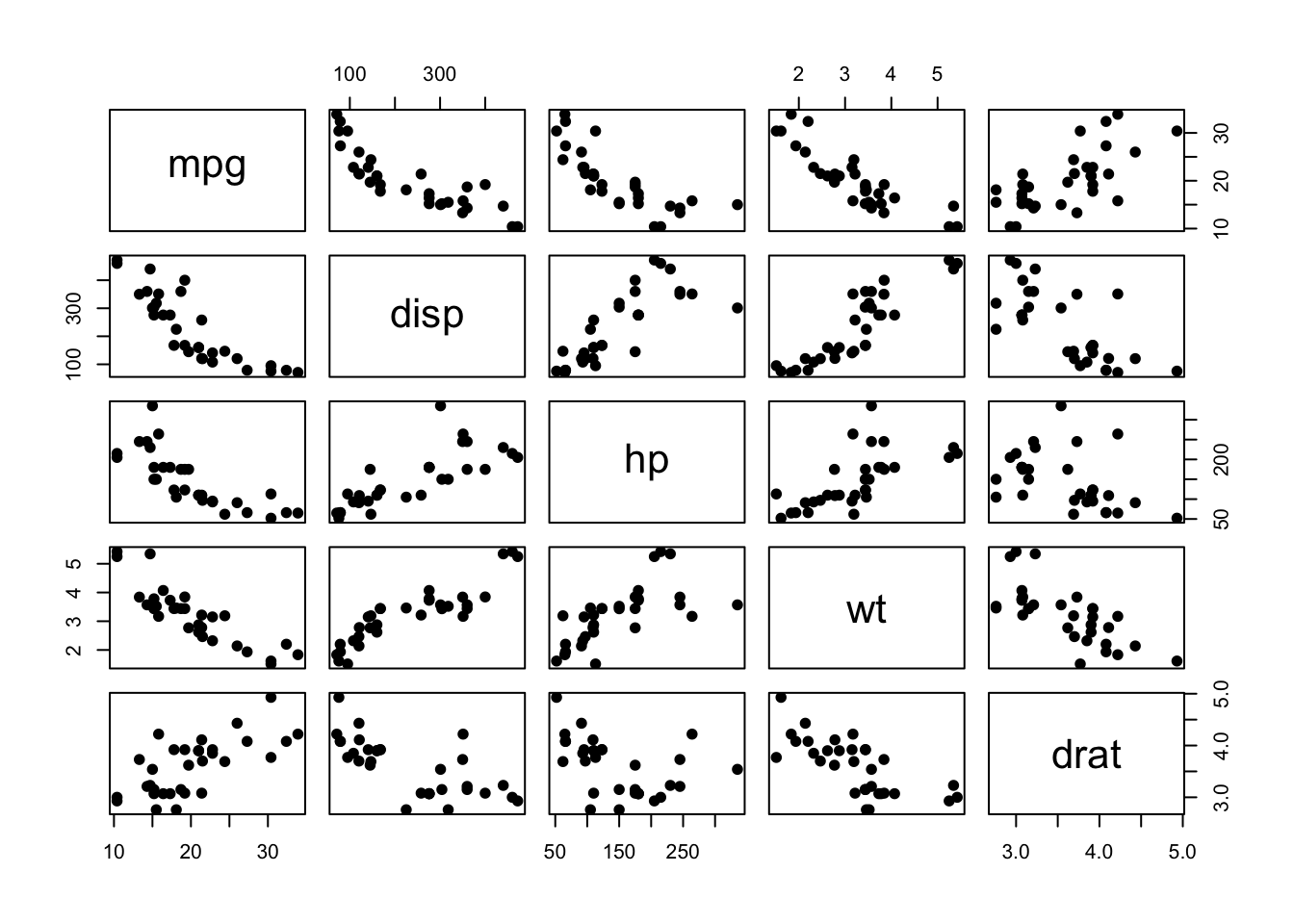
- Using the
mtcarsdata, run a linear regression to find the relationship between miles per gallon (mpg) on the left-hand-side as a function of displacement (disp), gross horsepower (hp), weight (wt), and rear axle ratio (drat) on the right-hand-side. That is, fit a regression of the following form:
\[ \widehat{mpg} = \hat{\beta_{0}} + \hat{\beta}_{1} disp + \hat{\beta}_{2}horse\_power + \hat{\beta}_{3}weight + \hat{\beta}_{4}drive\_ratio \]
model <- lm(mpg ~ disp + hp + wt + I(wt^2) + drat, data = mtcars)- For each of the following CLM assumptions, assess whether the assumption holds. Where possible, demonstrate multiple ways of assessing an assumption. When an assumption appears violated, state what steps you would take in response.
- I.I.D. data
- No perfect collinearity
- Linear conditional expectation
- Homoskedastic errors
- Normally distributed errors
# goal:
# consequence if violated:
# View(mtcars)# goal: we estimate the "right model"
# consequence if violated:
plot(resid(model), predict(model))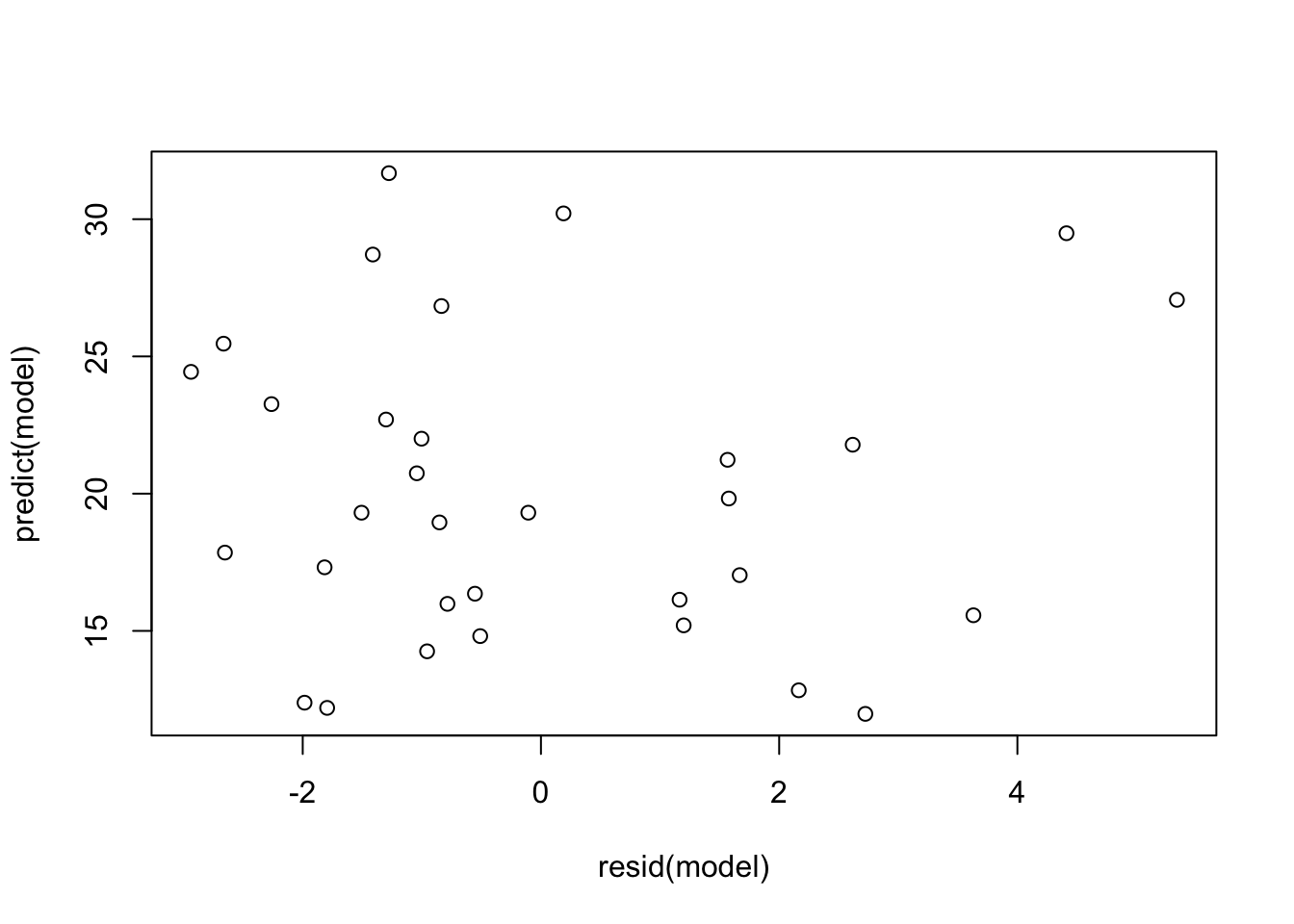
# plot(model)
# plot(mtcars$wt, resid(model))
# class(model)# goal:
# consequence if violated:
summary(model)
Call:
lm(formula = mpg ~ disp + hp + wt + I(wt^2) + drat, data = mtcars)
Residuals:
Min 1Q Median 3Q Max
-2.9378 -1.4353 -0.8102 1.5695 5.3393
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 44.709966 8.037242 5.563 7.66e-06 ***
disp -0.002895 0.010018 -0.289 0.774904
hp -0.025661 0.010947 -2.344 0.026990 *
wt -10.164720 2.637504 -3.854 0.000684 ***
I(wt^2) 0.950808 0.348886 2.725 0.011340 *
drat 0.498207 1.274372 0.391 0.699024
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 2.339 on 26 degrees of freedom
Multiple R-squared: 0.8737, Adjusted R-squared: 0.8494
F-statistic: 35.97 on 5 and 26 DF, p-value: 6.977e-11# goal:
# consequence if violated:
# We're sure they;re not constnat!
vcovHC(model, type = "const") (Intercept) disp hp wt
(Intercept) 64.59725500 -2.014384e-02 2.502973e-02 -1.665306e+01
disp -0.02014384 1.003602e-04 -7.134494e-05 -1.817698e-04
hp 0.02502973 -7.134494e-05 1.198420e-04 -7.251315e-03
wt -16.65306393 -1.817698e-04 -7.251315e-03 6.956429e+00
I(wt^2) 1.99212647 -8.590083e-04 1.167804e-03 -8.558110e-01
drat -8.99211329 4.928814e-03 -4.445799e-03 1.398580e+00
I(wt^2) drat
(Intercept) 1.9921264710 -8.992113294
disp -0.0008590083 0.004928814
hp 0.0011678043 -0.004445799
wt -0.8558109527 1.398580259
I(wt^2) 0.1217211286 -0.162563317
drat -0.1625633168 1.624023962vcovHC(model, type = "HC2") (Intercept) disp hp wt I(wt^2)
(Intercept) 25.25670069 -1.290457e-02 1.462811e-02 -8.255767929 1.066319640
disp -0.01290457 1.043367e-04 -9.728375e-05 0.003103165 -0.001286184
hp 0.01462811 -9.728375e-05 1.498401e-04 -0.005332482 0.001216345
wt -8.25576793 3.103165e-03 -5.332482e-03 4.403737911 -0.630955601
I(wt^2) 1.06631964 -1.286184e-03 1.216345e-03 -0.630955601 0.105757194
drat -2.57381895 2.188569e-03 -3.162583e-03 0.288839880 -0.022392165
drat
(Intercept) -2.573818955
disp 0.002188569
hp -0.003162583
wt 0.288839880
I(wt^2) -0.022392165
drat 0.514261588# goal:
# consequence if violated:
hist(resid(model))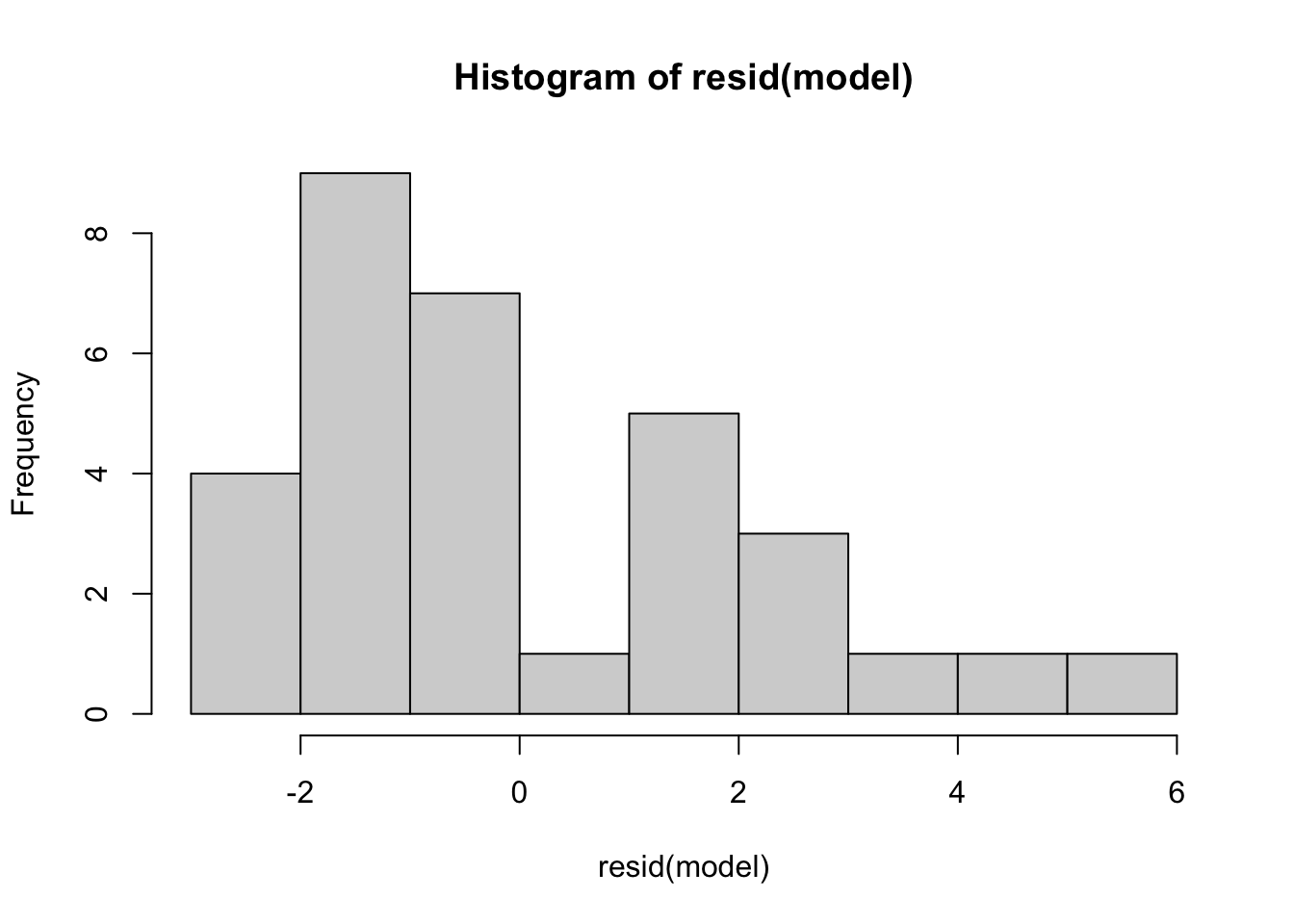
mean(resid(model))[1] -4.163336e-17In addition to the above, assess to what extent (imperfect) collinearity is affecting your inference.
Interpret the coefficient on horsepower.
Perform a hypothesis test to assess whether rear axle ratio has an effect on mpg. What assumptions need to be true for this hypothesis test to be informative? Are they?
Choose variable transformations (if any) for each variable, and try to better meet the assumptions of the CLM (which also maintaining the readability of your model).
(As time allows) report the results of both models in a nicely formatted regression table.